USA Today obtained of and published some quality ratings for Veterans Affairs medical centers. The article includes a searchable table but, being embedded in the article, it's a little cumbersome to use. It's not a huge data set so I wanted to see it all. Scoping out the page's source, the table is an embedded iframe so it can be viewed on its own.
I figured I'd poke around and see what it would take to get those rankings into a .csv. (Spoiler: a few lines of javascript.)
First thing was to pop open dev tools and take a look at the network tab to see if I could see the data being loaded. It was easy to spot (also, props to USA Today for the lightweight, fast-loading page):
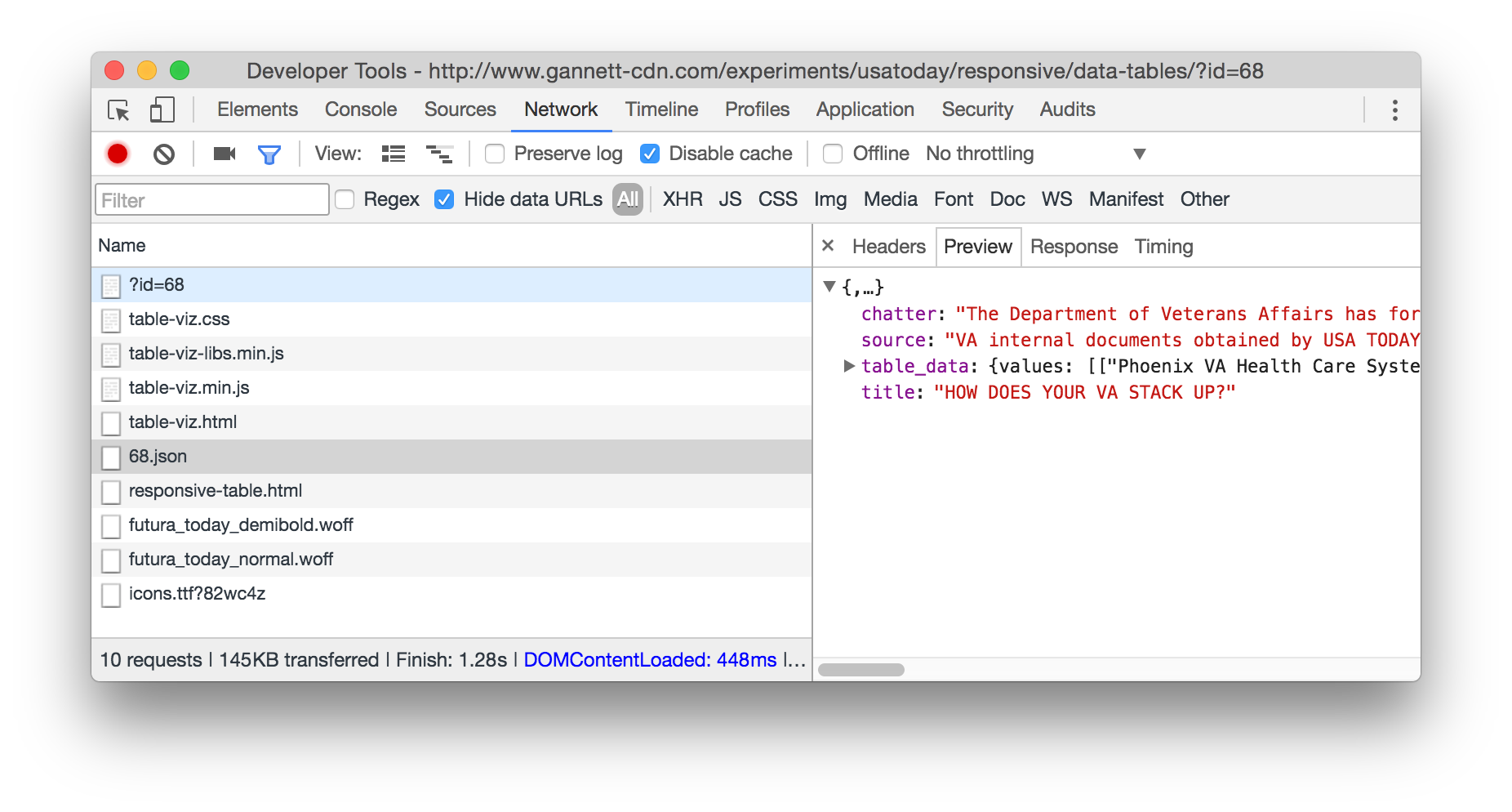
I knew where the data was ('data/68.json'), so I figured I could retrieve it, mess with it, then copy it out to a useful format. Here's the code to do that:
I think this is the first time I'd done an xhr in dev tools' console.
The code starts by retrieving the data from the URL I pulled out of the network tab. Once it arrives, the response is stored as a global for easy access.
The JSON is parsed and then the only relatively tricky part: converting an array of arrays to a csv-like structure. This is quick and dirty, but what happens is a loop runs through each row, and then each value in each row. If the value in a row contains a comma, the value is wrapped in double-quotes so that the embedded comma doesn't throw future parsing of the csv. Once embedded commas are handled, another loop (this time using map) converts the data from arrays to comma-separated strings.
To get csv-like data, table_data.fields is used to creat the header and passed to copy() so that it's on the clipboard. Then the data is joined with newlines and once again passed to copy() so it can be pasted into a gist.
Github's gist viewer is nice enough to format csv data as a table so it's all easily readable. Since it's so small, the browser's built in find functionality is adequate to search the data but there's also a search box available alongside the gist. If you want the data itself, click that button labeled "Raw" in the upper-right of the gist.