As part of a potential project, a friend sent me a link to a map that shows areas where the Federal Communications Commission (FCC) is incentivizing (subsidizing?) telecom companies to build out additional broadband infrastructure. At least I think that's what the map is showing.
As the map's legend indicates, the green splotches are areas where funding was accepted. The goal was to get the data behind the map tiles. The project didn't end up going anywhere but I was still curious about this data. The discussion I had didn't define what questions needed to be answered. Maybe we needed to know where there were CAF areas larger than 10 square miles. Or with a population over a certain threshold. Or within a certain distance to some existing infrastructure. These are questions that are much easier to answer, and answer accurately, if a vector form of a dataset is available as opposed to a set of images of the data.
{kind=link}
{kind=link}
After a few dead ends, I ended up on a "Price Cap Resources" page with a "List of Census Blocks Funded by Final Connect America Cost Model" link to download a file named CAM43_Supported_Locations.zip. It's a couple megabytes zipped and ~40MB unzipped. The .csv has a column named "CB" which I assumed meant census block.
The .csv has about 750k rows. Considering there are about 11 million census blocks, it seemed plausible that all the green on the aforelinked map corresponded to the ~750k block IDs in the .csv.
Now that I had a clear line of sight to source of the splotches, I came up with a plan:
- Download all census blocks.
- Split the original .csv by state.
- Create a list of block IDs per state.
- Use the list from step 3 as input to
ogr2ogrto create a new shapefile per state with only census blocks that are in the FCC funding areas. - Combine all the new shapefiles to create a single shapefile with all FCC areas.
- Maybe publish a new map with some interactivity?
At this point, I thought "smooth sailing from here!" Which was immediately followed by "that probably means the real problems are about to start." Pessimistic? A product of experience? Whatever, onward.
Step one was indeed easy enough thanks to a Census Bureau FTP server. Specifically, http://ftp2.census.gov/geo/tiger/TIGER2016/TABBLOCK/. There's a .zip for each state/territory. Altogether the .zip files come in just over seven GB (and took a couple attempts to download because my connection is flaky, or the FTP server is underpowered, or both).
Step two also didn't pose any major problems. Since there's a shapefile per state, I decided to process one state at a time rather than combining everything and trying to work with a USA-sized dataset. I split the .csv with the aptly named csv-split node module, which is something I wrote about when I was initially pondering pursuing this little data munging project.
With a .csv for each state, I was at a crossroads. When I started this, I tentatively told myself I'd prefer to avoid writing code beyond a shell script to do this processing. I struggled through some awk for step two before settling on a command line-based node module. Once I got to step three, I didn't want to fight through some combination of sed, awk and bash to read a .csv then build a where clause-like string for ogr2ogr to create a new shapefile. There was also the fact that the .csv files were named with two-letter state abbreviations while the zipped shapefiles used FIPS/ANSI codes. The idea of matching one to the other in bash was too much. So I started a node script to do the work.
To accomplish step three, I used csv-parse to read .csv files and plain JS to pull out the values from the column with the block ID. Here's a slightly simplified version of the code I ended up using:
const fs = require('fs')
const glob = require('glob')
const parse = require('csv-parse')
// Start by reading all .csv files.
glob(csvsFolder + csvFiles, null, (err, matches) => {
// Pull out blockIds from .csv files.
// Keep track of total number of .csv files and how many have been processed.
let csvsRead = 0
let totalCsvs = matches.length
// .csv files are read one at a time with readCsv().
// After reading a file, checkTotalCsvsProcessed is called.
// If there are more .csv files to read, readCsv is called.
// This continues (recursion) until all .CSVs are processed.
let checkTotalCsvsProcessed = () => {
csvsRead += 1
if ( csvsRead < totalCsvs ) {
readCsv(matches[csvsRead], checkTotalCsvsProcessed)
} else {
console.log('Read all .csv files with block IDs.')
}
}
let readCsv = (csv, callback) => {
console.log('Reading: ', csv)
let csvData = [];
fs.createReadStream(csv).pipe(parse())
.on('data', row => {
csvData.push(row)
})
.on('end', () => {
// Keep only the value from the first column because that is the block ID.
csvData = csvData.map(row => row[0])
// Remove header row.
csvData.shift()
// ...removed stuff, not relevant yet
let currentState = csv.replace(csvsFolder, '').replace('.csv', '')
// blockIdBatches is discussed later in the post.
blockIds[currentState] = blockIdBatches
callback()
});
}
readCsv(matches[csvsRead], checkTotalCsvsProcessed)
})
One point to call out from the chunk above is the pattern of recursively calling a function to process items in serial. I find myself doing this a lot (and I used it a couple more times for other parts of this project) because it fits in my brain nicely and it works. This is slower than ripping through matches with a forEach. Since there's some async file I/O in readCsv, I don't want to try to read all the files concurrently and (potentially) overwhelm my machine. Plus, this way, I've got an example of recursion that isn't a fibonacci sequence generator.
readCsv() kicks things off and gets checkTotalCsvsProcessed() as a callback. Once a file is processed, checkTotalCsvsProcessed() runs to see if there's more work to do. When there's more, readCsv() is called again with checkTotalCsvsProcessed() as a callback. This continues until everything's done.
With code to pull the relevant info from the pile of .csv files, I moved on to thinking about those census blocks. As I already mentioned, the files from the Census Bureau have FIPS codes in their names while the .csv file used two letter state abbreviations. This wasn't a step in the initial plan, but I needed to make a lookup table to go from state abbreviation to FIPS code. Here's what I did:
- Found the Wikipedia page for FIPS codes
- Opened my browser's dev tools (cmd + opt + i, ⌘⌥ + i)
- Tinkered a bit and settled on this code to grab FIPS code and state abbreviations from the Wikipedia page:
var lookup = {}
var rows = document.querySelectorAll('table.wikitable.sortable tr')
rows.forEach(function(row) {
var cells = row.querySelectorAll('td');
if ( cells.length && cells[1].innerText && cells[2].innerText ) {
lookup[cells[1].innerText] = cells[2].innerText;
}
});
copy(lookup)
- Switched to my editor, opened a new file and pasted the JSON into a file and saved it as
state-fips.json. The same JSON is over on github in a gist.
That last line, copy(lookup), is still one of my favorite dev tools tips.
Now that I had a simple state abbreviation to FIPS code lookup, which is read this way:
// key: value corresponds to state_abbr: fips_code
const stateToFips = JSON.parse(fs.readFileSync('state-fips.json'))
I could get back to step four. And since I was already off the shell script-only wagon, I kept writing javascript.
I knew that ogr2ogr could handle receiving a list of block IDs and output a new shapefile but I didn't know how to call it from node. Enter child-process, specifically child-process.exec().
After a little experimenting with child-process.exec(), as well as unzip, I felt like I was pretty close to firing off a script and generating one shapefile per state with census blocks of interest. I was wrong.
First up was Error: spawn E2BIG. One quick search and it's clear that the ogr2ogr command being generated was too big. How long is too long for a single command, anyway? Running getconf ARG_MAX in my terminal tells me 262,144. So I was doing something that was creating a command that was more than a quarter million characters long. At one point I logged the length of the generated commands instead of trying to execute them. The only product of that exercise was me feeling shame. I clearly needed to break things up.
There is a comment about blockIdBatches in the code block for reading .csv files. The blockIdBatches variable is used to keep track of chunks of block IDs so that later commands can be generated that will come in below the length limit defined by ARG_MAX. In other words, block IDs for a state had to be split into smaller chunks.
I tweaked the code to do a few thousand block IDs at a time instead of an entire state to stay under ARG_MAX. Then I got a new error:
ERROR 1: SQL Expression Parsing Error: memory exhausted. Occured around : 54','191315602001058','191315602001078','191315602001085','191315602001094','191. A little more searching and it was clear my commands were still too long. This time I was running into an ogr2ogr limitation rather than an OS-level or shell limitation. Splitting the blocks into groups of 1,000 ended up being my work around.
Here is the complete readCsv() function (blockIds is a global):
let readCsv = (csv, callback) => {
console.log('Reading: ', csv)
let csvData = [];
fs.createReadStream(csv).pipe(parse())
.on('data', row => {
csvData.push(row)
})
.on('end', () => {
// Keep only the value from the first column because that is the block ID.
csvData = csvData.map(row => row[0])
// Remove header row.
csvData.shift()
// Split data into batches of 1k.
//
// The lists of block IDs will be used in an ogr2ogr where clause.
// The ogr2ogr command will be very long.
// If it's over `getconf ARG_MAX`, trying to exec() it will throw:
// Error: spawn E2BIG
// OSX's limit is 262144.
// Using 1k block IDs per batch stays way under that.
//
// ogr2ogr was also throwing:
// ogr2ogr stderr ERROR 1: SQL Expression Parsing Error: memory exhausted. Occured around :
// 54','191315602001058','191315602001078','191315602001085','191315602001094','191
//
// Using batches of 1k avoids that error too.
let blockIdBatches = []
let batchSize = 1000
let batchCount = csvData.length / batchSize
let batchStart = 0
let batchEnd = batchSize
if ( csvData.length > batchSize ) {
// Pull out chunks of 10k items.
while ( batchStart < csvData.length ) {
blockIdBatches.push(csvData.slice(batchStart, batchEnd))
batchStart += batchSize
batchEnd += batchSize
}
} else {
blockIdBatches.push(csvData)
}
let currentState = csv.replace(csvsFolder, '').replace('.csv', '')
blockIds[currentState] = blockIdBatches
callback()
});
}
All the csv files are read, the block IDs of interest are stored in an object so the next thing was to start cranking through batches of IDs and creating new shapefiles.
In the final script that does all the processing, the else branch in checkTotalCsvsProcessed() calls a function boringly named filterCensusBlocks(). Here's what that looks like:
let filterCensusBlocks = () => {
// Find all the zipped Census block shapefiles.
glob(blocksFolder + zipFiles, null, (err, matches) => {
matches.forEach(f => {
// Strip out the folder name, split the file name to find the FIPS code.
let pieces = f.replace(blocksFolder, '').split('_')
// console.log(f, 'corresponds to', fipsToState[pieces[fipsPosition]])
// Keep track of zip files to know what to unzip.
if ( stateCsvs.indexOf(fipsToState[pieces[fipsPosition]]) > -1 ) {
filesToUnzip.push({
state: fipsToState[pieces[fipsPosition]],
name: f
})
}
})
// Same pattern as above where .csv files were read and processed.
// Keep track of how many shapefiles there are to unzip, then:
// - unzip Census block shapefiles one at a time
// - use ogr2ogr to create a new shapefile with blocks of interest
// - delete original shapefile
// - repeat until all zipped shapefiles are processed.
let unzipped = 0
let total = filesToUnzip.length
// total = 1
let checkTotalUnzipped = () => {
unzipped += 1
if ( unzipped < total ) {
unzipBlocks(filesToUnzip[unzipped], checkTotalUnzipped)
} else {
console.log('Unzipped and processed all!', unzipped, total)
}
}
let unzipBlocks = (f, callback) => {
console.log('unzipBlocks', f)
fs.createReadStream(f.name).pipe(unzip.Parse()).on('entry', (entry) => {
let parts = entry.path.split('.');
let outName = `${f.state}_all_blocks.${parts[parts.length - 1]}`
// console.log('processing', outName)
let stateBlocks = unzippedFolder + outName
entry.pipe(fs.createWriteStream(stateBlocks));
}).on('close', () => {
// Unzipping is finished.
// Refer to the corresponding array of block IDs to keep in blockIds.
// Again, track total things to process, call a function recursively
// until everything is processed.
let batchesProcessed = 0
let checkBatchesProcessed = () => {
batchesProcessed += 1
if ( batchesProcessed < blockIds[f.state].length ) {
exportBlocks(batchesProcessed, checkBatchesProcessed)
} else {
console.log('DELETING', f.state)
rimraf(unzippedFolder, () => {
fs.mkdir(unzippedFolder, callback)
})
}
}
let exportBlocks = (batch, callback) => {
// Build an ogr2ogr command. Wrap block IDs in single-quotes.
let ids = blockIds[f.state][batch].map(id => `'${id}'`).join(',')
// Build a where clause.
let where = `"GEOID10 IN (${ids})"`
// Execute ogr2ogr -where "GEOID10 IN (${ids})" output input.
let output = `${filteredBlocksFolder}CAF_${f.state}_${batch}.shp`
let input = `${unzippedFolder}${f.state}_all_blocks.shp`
let ogr2ogr = `ogr2ogr -where ${where} ${output} ${input}`
exec(ogr2ogr, (error, stdout, stderr) => {
// console.log('ogr2ogr error', error)
// console.log('ogr2ogr stdout', stdout)
// console.log('ogr2ogr stderr', stderr)
console.log(f.state, 'batch', batch, 'finished.')
callback()
})
}
exportBlocks(batchesProcessed, checkBatchesProcessed)
})
}
unzipBlocks(filesToUnzip[unzipped], checkTotalUnzipped)
})
}
There's a lot happening, and it should probably be refactored. I added comments to help navigate all the nested code. The part to focus on is the usage of recursion I mentioned once already. There are two more instances: one when tracking if there are more shapefiles to unzip and again when processing batches of census block IDs to pull out of state-level census block shapefiles. There's also some clean up happening once processing of a state's census blocks finished via rimraf to delete the original shapefile with all census blocks for a state.
At this point in the process, there is a directory of shapefiles that, collectively, make up all the block IDs from the FCC .csv. Success? Partially! In that initial plan, I said "create a new shapefile per state" but instead I'd ended up with several shapefiles per state. Since my script was getting pretty long (more than a couple screens worth of code), I decided it was time for a new script to handle merging the shapefiles with all the batches.
I again used state-fips.json to get a list of state abbreviations. For each state, glob creates a list of shapefiles that have batches of census blocks. ogr2ogr is used again to merge all shapefiles for a state. For the umpteenth time, the pattern of recursively processing states until all the work is done is used. Here's the code:
const fs = require('fs')
const path = require('path')
const exec = require('child_process').exec
const glob = require('glob')
const blockBatches = 'filtered-census-blocks'
const out = 'filtered-merged'
const prefix = 'CAF_'
const format = '-f \'ESRI Shapefile\''
const stateToFips = JSON.parse(fs.readFileSync('state-fips.json'))
let processedStates = 0
let allStates = Object.keys(stateToFips)
let processedBatches = 0
let currentBatches = null
let currentShp = null
let checkProcessed = () => {
if ( processedStates < allStates.length ) {
// if ( processedStates < 2 ) {
processState()
} else {
console.log('\nFinished.')
}
}
let processState = () => {
let current = allStates[processedStates];
console.log(current)
// Look for a all .shp's for the current state.
glob(`${blockBatches}${path.sep}${prefix}${current}*.shp`, null, (err, matches) => {
// No matches means no shapefiles for a state/territory.
if ( matches.length === 0 ) {
processedStates += 1
checkProcessed()
return
}
currentShp = `${out}${path.sep}${current}.shp`
// Copy the first file then merge the rest into the copy.
// create: ogr2ogr -f 'ESRI Shapefile' $file $i
let create = `ogr2ogr ${format} ${currentShp} ${matches[0]}`
console.log(create)
exec(create, (error, stdout, stderr) => {
// All shapefiles but the first.
currentBatches = matches.slice(1)
if ( currentBatches.length === 0 ) {
processedStates += 1
checkProcessed()
return
}
mergeBatch(currentShp, currentBatches[processedBatches])
})
})
}
let checkBatches = () => {
if ( processedBatches < currentBatches.length ) {
mergeBatch(currentShp, currentBatches[processedBatches])
} else {
processedBatches = 0
currentBatches = null
processedStates += 1
checkProcessed()
}
}
let mergeBatch = (target, batch) => {
// merge: ogr2ogr -f 'ESRI Shapefile' -update -append $file $i
let append = `ogr2ogr ${format} -update -append ${currentShp} ${batch}`
console.log('\t', append)
exec(append, (error, stdout, stderr) => {
processedBatches += 1
checkBatches()
})
}
checkProcessed()
With that, step four is in the bag. The filtered-merged folder has one shapefile per state with only the census blocks from the FCC .csv. Total size on disk for all the new shapefiles is about a gig and a half.
It wasn't much more effort to merge everything into a single shapefile:
const path = require('path')
const exec = require('child_process').exec
const glob = require('glob')
const stateBatches = 'filtered-merged'
const outFolder = 'filtered-usa'
const out = 'usa-fcc-CAF-blocks'
const format = '-f \'ESRI Shapefile\''
let allStates = null
let processedStates = 0
let targetShp = null
let start = () => {
// Get all shapefiles.
glob(`${stateBatches}${path.sep}*.shp`, null, (err, matches) => {
allStates = matches
targetShp = `${outFolder}${path.sep}${out}.shp`
// Copy the first file then merge the rest into the copy.
// create: ogr2ogr -f 'ESRI Shapefile' $file $i
let create = `ogr2ogr ${format} ${targetShp} ${matches[0]}`
console.log(create)
exec(create, (error, stdout, stderr) => {
mergeState(targetShp, allStates[processedStates])
})
})
}
let mergeState = (target, batch) => {
// merge: ogr2ogr -f 'ESRI Shapefile' -update -append $file $i
let append = `ogr2ogr ${format} -update -append ${targetShp} ${batch}`
console.log('\t', append)
exec(append, (error, stdout, stderr) => {
processedStates += 1
if ( processedStates < allStates.length ){
mergeState(targetShp, allStates[processedStates])
} else {
console.log('\nFinished.')
}
})
}
start()
Since this is a simpler task, I could have saved myself a little time and merged everything with bash but I already had a bunch of javascript, why not a little more.
Now there is a single 1.5 GB shapefile on disk with about 750K features. Time for some spot checking to see if all this work had the desired result.
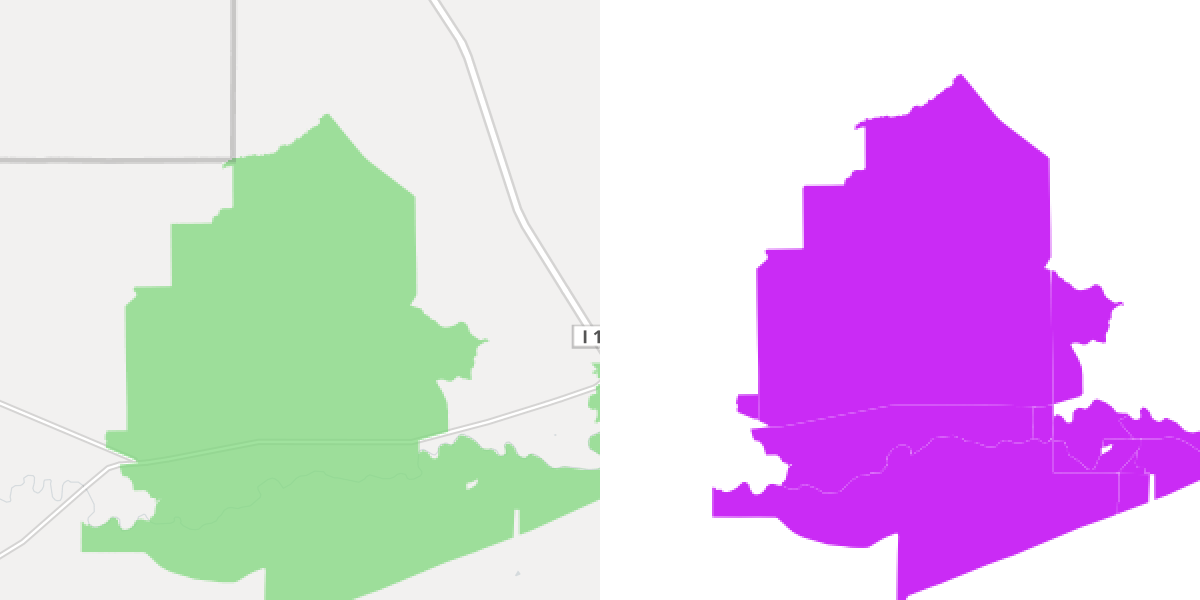
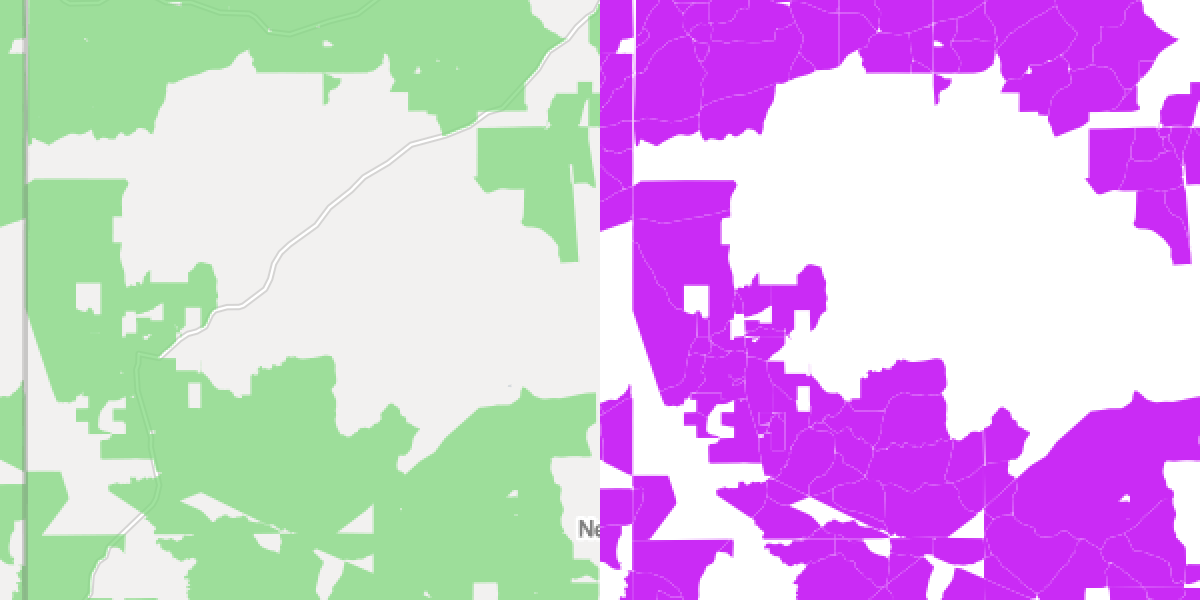
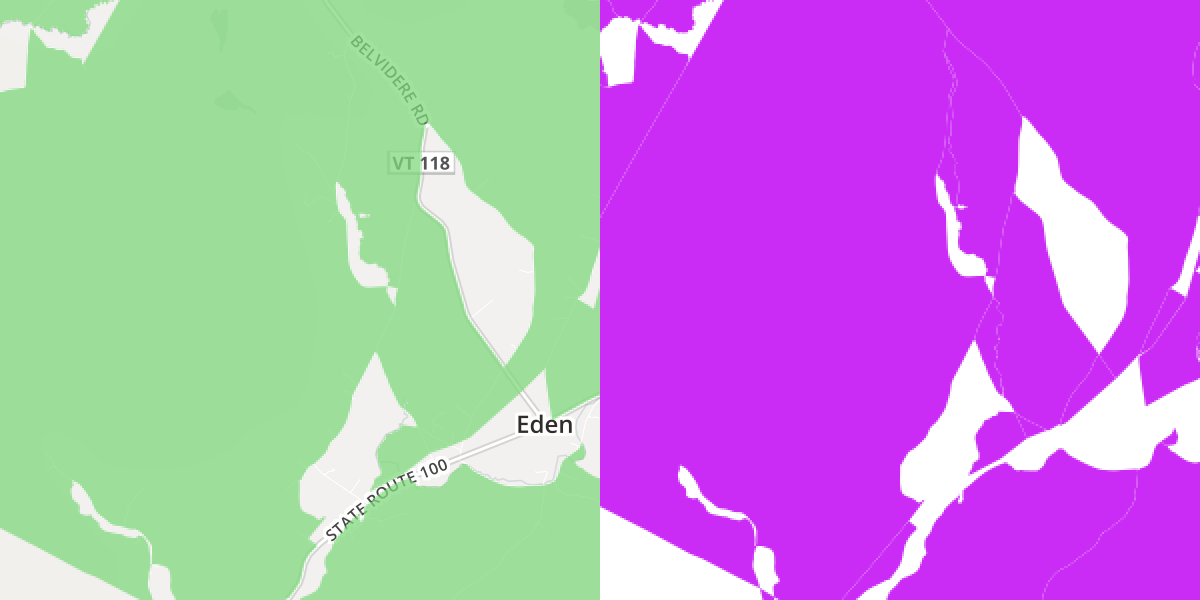
I compared several several locations on the FCC map and my final shapefile. Below are screen shots of a few areas. FCC stuff on the left, same areas in the final shapefile I created on the right.
Outside Great Falls, Montana:
Some of Newton County, Mississippi:
An area around Eden, VT:
I don't know of a quick or free (would also consider cheap!) way to publish a 1.5 GB shapefile in an interactive map. Since I have all those state-level files, I decided to convert one of the smaller ones, Nevada, to GeoJSON and drop it into geojson.io. Poke at the features either on bl.ocks.org or gist.github.com. I'll give myself partial credit on step six.
It's worth noting that not a single step went off without a hitch. To recap:
- Step one: multiple failed download attempts.
- Step two: multiple approaches using awk, settled on a node module.
- Step three: resorted to using JS, then
ARG_MAXand thenogr2ogrmemory erorrs. - Step four: continued using JS, required additional processing and merging.
- Step five: the quickest step, couple iterations and was done because it was so similar to step four.
- Step six: so...where's a good place to upload a 1.5GB shapefile and serve it?
Other things to mention:
- coding style: there's some ES6/ES2015 stuff happening and I'm not using semi-colons. I don't have a vim vs. emacs-level opinion on semi-colons so I don't use them when I'm writing "modern" JS.
- this post is too long: not only did I underestimate the amount of work it would be to carve out a few hundred thousand census blocks from the full dataset, I underestimated the amount of words it would take describe the process. No one reads this blog except future me so I'm OK with these failures.
- Why did I choose to process so many things in serial? Empathy for the machine, I guess. And recursion is fun.
- The code is boring and sometimes repetitive in the hopes that it's easy to understand when I need to do something similar in the future.
- I didn't put this stuff in a repo because it's a one-off and the scripts depend on several gigs of data. All the code that does the real work is available via two gists: create-shapefiles-with-FCC-census-blocks.js and merge-batches-into-state-shapefiles.js.
There's probably an opportunity to make something that simplifies some or all of this process but it's probably not going to be me that creates it. This feels too niche to generalize and each project will always have some custom data wrangling. There are already heavy apps with very clicky GUIs that can do this work but I don't like them (many reasons, primarily that it takes too much discipline to maintain an accurate record of a process). One alternative that probably makes all of this more efficient: put everything in a spatial db, write one statement to pull 750k rows out of a table with millions then export to your preferred interchange format. Sounds easy enough...